DeepSeek推V3.2与Speciale,推理与效能直逼GPT|5、Gemini 3
DeepSeek 于12/2 新推出两款模型,分别是DeepSeek|V3.2,与专攻数学推理的DeepSeek|V3.2|Speciale。官方表示,这两款模型延续当初的实验方向,目的是在推理能力、工具用与长考虑能力上全方位升级。 DeepSeek 也强调,正式版V3.2 在多项推理测试表现上已能与GPT|5、Gemini|3 Pro 相提并论,而Speciale 版本在数学与资讯竞赛的表现达到国际金牌水准。
实验版领路,正式版V3.2 接棒亮相
DeepSeek 在9 月推出V3.2|Exp 时,就把它定位为迈向下一代人工智能 的实验平台。这次推出的正式版DeepSeek|V3.2,命名不再加上「Exp」,象征功能更成熟。
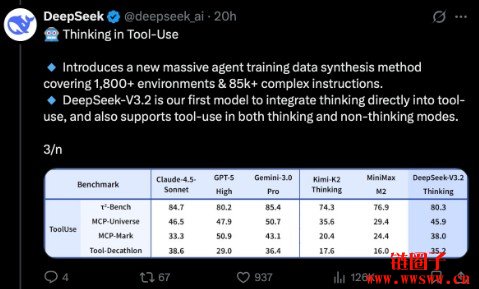
官方说明,新版V3.2 在多项推理测试上的表现与GPT|5 和Gemini|3 Pro 相近,并特别强调这是他们首次把「考虑模式」与「工具应用」紧密整理的模型,且同时支援考虑模式与非考虑模式。从下图可得知:
「DeepSeek|V3.2 透过基准测试表证明其工具用能力已能与GPT|5、Gemini|3 Pro 等顶尖模型并列。」
推理能力再升级,工具整理成最大闪光点
DeepSeek 表示,V3.2 的大闪光点,是能把推理过程与工具用合并运作。换句话说,模型在考虑某件事情的同时,也能调用搜寻引擎、计算机、程式码实行器等外部工具,让整体任务处置过程更完整、更自主,也更接近人类处置问题的方法。
Speciale 专注长推理,数学表现达金牌等级
除去标准版V3.2,DeepSeek 同时推出另一个版本DeepSeek|V3.2|Speciale。这个版本专门为高困难程度的数学推理与长期考虑设计。
官方的定位,是期望探索开源模型推理能力的极限,甚至看看模型本身能达到什么边界。从成绩来看,Speciale 在国际数学奥林匹亚(IMO)、国际资讯奥林匹亚(IOI) 等测验竞赛中达到金牌等级,推理表现则与谷歌 最新的Gemini|3 Pro 旗鼓相当。从下图可得知:
「DeepSeek|V3.2|Speciale 的推理能力已达到国际数学与资讯竞赛的金牌水准,在多项推理与程式竞赛基准测试中表现超越或匹敌GPT|5、Gemini|3 Pro 与Kimi|K2。」

新练习方法揭秘,人工智能 代理能力再强化
在模型以外,DeepSeek 也公开一项新的研究成就,也就是他们已经打造新的办法来练习人工智能 代理。这种代理能自己与外部环境互动、剖析资料、做出判断,无需人类持续给指令。
DeepSeek 强调,这是他们为了让人工智能 实行效率更高、反应更快所设计的基础技术。
延续1月声量,研发步伐持续加速
DeepSeek 在今年1 月因一款突破性模型引发全球关注。这次的V3.2 系列,也是他们在那次成功后延续研究动能的最新成就。就在推出V3.2 之前,DeepSeek 才在上周发布DeepSeekMath|V2,一款专攻数学定理证明的开源模型,显示他们正在推理与数学范围持续加大。
技术报告出炉,V3.2 推理力接近GPT|5 与Kimi
DeepSeek 也同步发布技术报告《DeepSeek|V3.2: Pushing the Frontier of Open Large Language Models》,指出V3.2 在多项推理基准测试中与GPT|5 和Kimi|k2|thinking 表现相似。
这份报告也强调,中国当地开源模型在推理范围的竞争优势仍然与国际顶尖模型维持在同一级距。
下一篇:没有了
免责声明:
1.本文内容综合整理自互联网,观点仅代表作者本人,不代表本站立场。
2.资讯内容不构成投资建议,投资者应独立决策并自行承担风险。