Cloudflare大当机!官方如何说?修复程度到哪了?
Cloudflare大规模问题在18日晚间导致多起服务中断服务,官方表示「事件已解决」,多数网站已渐渐恢复功能。
Cloudflare大当机!官方如何说?
重点1、Cloudflare大规模问题在18日晚间导致多起服务中断服务,官方表示「事件已解决」,多数网站恢复。
重点2、依据国际互联网监测平台Downdetectot统计,包含社群平台X、ChatGPT、Spotify等都一度遭到问题影响,相继出现「内部伺服器错误」(HTTP 500 Internal Server Error)与封锁误判。
重点3、Cloudflare 状况页更新多次,历经「调查中、工具部分恢复」到宣告修复,截至台湾时间18日晚间11时许,官方表示服务「看上去已恢复」,现在持续监控中。
全球要紧互联网基础设施厂家Cloudflare于11月18日晚间爆发全球性互联网问题,致使数以千计大型网站和应用程式陷入瘫痪。
此次问题紧急冲击依靠Cloudflare的各类重点服务,包含社群平台X、ChatGPT、Spotify、云端平台AWS、LOL、谷歌、Canva、Azure等,前端页面都一度遭到影响,出现大规模连线失败及系统错误,冲击范围遍及美国、欧洲至亚太等多地。

依据国际互联网监测平台Downdetector统计,包含社群平台X、ChatGPT、Spotify等都一度遭到问题影响,相继出现「内部伺服器错误」(HTTP 500 Internal Server Error)与封锁误判。图/Downdetector
不少用户在Downdetector反映没办法登入网站、网页元件遗失,甚至称「全世界都遭到影响」。
至于Cloudflare当机,为什么一次对这么多平台有影响?缘由在于Cloudflare是很多网站的「中介层」(CDN、DNS、安全与边缘运算),因此其全球互联网一出问题,经它转送或分析的流量就会同时受影响。
白话来讲,不少网站把自己连到Cloudflare,请求会先经过它的互联网再回到原站。 Cloudflare提供加速的CDN、挡攻击的WAF与DDoS防护、助你「找到网站地址」的DNS,甚至在边缘助你跑程式。所以它其实是互联网上的大型「中介层」。
一旦这个中介层在某一环节出问题(譬如路由、代理或边缘服务问题),经过它的很多网站就一块出现500错误、连不上或变超慢,比喻来讲就是「经过这个交流道的车」都会受影响,事实上就是不少平台一块当机。
Cloudflare官方如何说?
Cloudflare 现在已飞速于系统状况网站公告本次全球当机事件。根据最新状况,官方强调「大家觉得事件已解决」,但部分顾客可能仍遇见登入或用Cloudflare 控制面板的有关问题,「正在努力修复,并持续监控问题。」
回顾官方状况消息,修复事件的重点时间点如下(以下皆以UTC协调世界时为准):
13:09 UTC:已定位问题并开始推行修复。13:13 UTC:Access 与WARP 错误率回到事件前水准;伦敦的WARP 用重新启用。
14:34 UTC:已部署变更,仪表板服务恢复,但广泛应用服务仍在修复中。
14:42 UTC:修复已推行,事件「相信已解决」,进入监控。
14:57 UTC:仍有部分顾客登入/用仪表板出现问题,持续处置与监控。
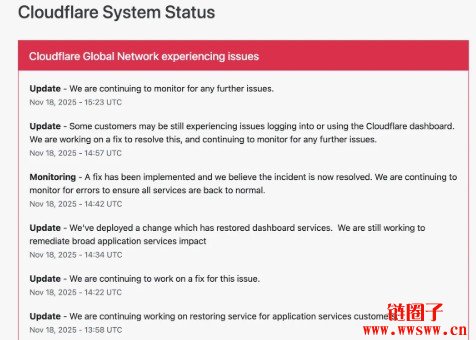
Cloudflare 现在已于系统状况网站公告本次全球当机事件。图/Downdetector
值得庆幸的是,大规模当机时间为台湾时间深夜,对于广大工薪族群来讲应无太大冲击。不少网友在Threads上发文指出「互联网上还有活人吗?」、「那我今晚可以不需要工作了吗?」也有人表明连线正常,「但我不想工作啦!」
上一篇:K网/Kraken交易平台注册不了的容易见到问题分析与解决方法
下一篇:没有了
免责声明:
1.本文内容综合整理自互联网,观点仅代表作者本人,不代表本站立场。
2.资讯内容不构成投资建议,投资者应独立决策并自行承担风险。